Abstract
- Faster R-CNN과 SSD framework에서 사용하는 anchor box와 ground-truth box의 매칭을 기준으로 하는 IoU 방식은 scene text detection을 하는 데에 적합하지 않다.
- 다양한 anchor box scale, ratio, orientations을 요구하는 scene text detection 문제를 해결하기 위해, 이 논문에서는 anchor-free region proposal network(AF-RPN)을 제안하였다.
Introduction
- visual intelligent applications의 수요가 증가하면서 text detection의 수요가 많아지고 있다. 하지만 text의 색, 폰트, 방향, 언어, 크기뿐만 아니라 일반적인 scene에서 연조(low contrast), 저해상도(low resolution), 폐색(Occlusion) 등의 text detection에서 풀어야 하는 문제들이 남아있다.
- Faster R-CNN과 SSD가 text detection 문제를 해결하기 위해 사용되지만, reference box가 사용되는 anchor box 메커니즘 상 text detection 문제에 유연하게 접근할 수 없다.
- 이 문제를 해결하기 위해, DenseBox의 anchor-free idea와 Faster R-CNN의 framework를 접목해, AF-RPN을 제안하였다.

- 특정 conv feature map의 각 pixel은 Fig1 그림처럼 원본 이미지에 sliding point라고 불리는 하나의 point로 대응된다.
- 각 sliding point는 text region의 위치하고, AF-RPN는 관련 text instance의 bounding의 꼭짓점까지에 offset을 예측한다.
- 이 방법은 직접 anchor box를 조작해야 되는 기존 방법의 어려움을 없애고, sliding point가 ground-truth bounding box’s의 core region에 있는지 결정하기만 하면 된다.
Anchor-free Region Proposal Network
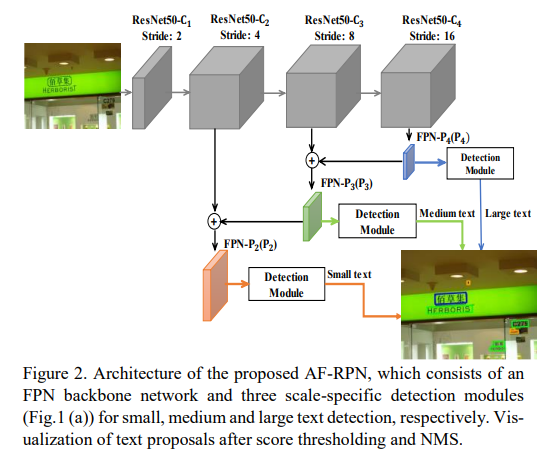
논문에서 제안된 AF-RPN은 하나의 backbone network와 3개의 detection 모듈로 구성되어있다. backbone network는 input image에 대한 multi-scale conv feature을 추출한다. 3개의 detection 모듈은 서로 다른 피라미드 레벨에 달려있고, 각각 small, medium, large text를 detection 하도록 디자인되었다. 또한 각 모듈은 작은 네트워크를 포함하며, output layer로 text/non-text 분류를 하는 layer와 bounding box regression을 하는 layer로 이루어져있다.
Network Architecture of AF-RPN
- backbone network로는 하나의 해상도 이미지로 여러 스케일의 feature를 얻을 수 있는 FPN network를 사용하였다.
- 피라미드의 각 레벨은 특정 범위 내의 객체를 탐지하는데 사용되어진다
- ResNet50 구조에 FPN을 활용하였고, feature 피라미드를 각각 P2, P3, P4 3개의 레벨, 4,8,16 strides로 구성하였다.
- P5는 text detection task의 적합하지 않아서 사용하지 않았다.
- 모든 feature pyramid level의 channel은 256 대신 512를 사용하였다.
- 3개의 detection 모듈은 각각 P2, P3, P4의 붙어있다.
- 각각의 detection 모듈은 작은 network로 text/non-text classification과 bounding box regression을 수행한다.
- 그 작은 network에는 text 점수와 bounding box 예측에 사용되는 2개의 1 by 1 conv에 뒤이어 3 by 3의 conv이 사용된다.
- 이 논문에서는 3개의 detection 모듈이 각각 small, medium, large text를 탐지하도록 디자인하는 scale-friendly 학습 방법이 제안된다.
- 각 모듈에서 classification 과 regression 문제를 더 효과적으로 다룰 수 있고, large scale에 text에 대한 문제도 잘 다룰 수 있게 된다.
Scale-friendly Learning

- 관찰 결과 피라미드 레벨에서 feature의 가장 짧은 부분이 3 pixels 보다 작으면, detection module의 성능이 급격하게 저하된다.
- Fig3에서 노란색 bounding box가 둘러져 있는 text의 가장 짧은 부분은 원본 이미지에서 16 pixel이다.
- raw image가 각각 0.75, 0.50, 0.25로 down sampling 되었을 때, P2(stride=4)에서 G'의 feature height는 각각(16->12->3, 16->8->2, 16->4->1)이 된다. (Fig3.(a),(b))
- Fig.3(c)로부터, input image의 text height(가장 짧은 부분)가 12 pixel 보다 작을 때, 아무리 많은 작은 text instance들이 있어도 proposal을 추출할 수 없다는 것을 알 수 있다.
- 이러한 관찰 결과에 따라서, 피라미드 레벨에서 text instance를 할당할 때, feature의 짧은 부분이 3px 이상인지 확인해야 한다.
- P2, P3, P4의 stride는 각각 4, 8, 16 pixel이므로, text instance의 가장 짧은 부분이 최소 12, 24, 48 pixel로 할당되어야 한다.
- 결과적으로, 가장 짧은 면을 기준으로 text instance를 small text(4px-24px), medium text(24px-48px), large text(>48px)로 분류할 수 있다.
Label Generation
- text detection 작업의 text instance는 일반적으로 사각형 또는 axis-align bounding box 단어 단위로 라벨이 붙혀진다.
- 이 작업을 더 쉽게 하기 위해서, 논문에서는 새로운 gt box로 minimum enclosing box들을 사용하였다.
- text/non-text 분류에 대해서 background 노이즈에 대한 영향을 줄이기 위해서, 각 gt 사각형의 모든 면들을 0.5 ~ 0.8로 스케일링하여 core text region을 만들었다. (Fig 1.(b) yellow solid line)
- bounding box가 충분히 타이트하지 않으면, 둘러 싸고 있는 background가 gt box안에 포함될 수 밖에 없다.
- text/non-text 분류에 대해서 background 노이즈에 대한 영향을 줄이기 위해서, 각 gt 사각형의 모든 면들을 0.5 ~ 0.8로 스케일링하여 core text region을 만들었다. (Fig 1.(b) yellow solid line)
- positive, don’t care, negative
- sliding point가 core region 안에 있는 경우 positive로 학습한다.
- sliding point가 core region 밖에 있지만, gt box 안에 있을 때는 don’t care(ignored)로 학습한다.
- sliding point가 gt box 밖에 있는 경우 negative로 학습한다.
- 각각의 positive sliding point들이 직접 bounding box 좌표를 예측한다.
- 𝑝𝑡 = (𝑥𝑡 , 𝑦𝑡) denote a positive sliding point, which is located in a ground-truth rectangle G
- {𝑝𝑖 = (𝑥𝑖 , 𝑦𝑖 |𝑖 ∈ {1,2,3,4}} denote the vertices of G
- Then the coordinate offsets from 𝑝𝑡 to G ’s vertices can be denoted as {∆𝑖= (∆𝑥𝑖 , ∆𝑦𝑖 )|𝑖 ∈ {1,2,3,4}},where ∆𝑥𝑖= (𝑥𝑖 − 𝑥𝑡) and ∆𝑦𝑖= (𝑦𝑖 − 𝑦𝑡)
- ∆𝑥𝑖= (𝑥𝑖 − 𝑥𝑡) /𝑛𝑜𝑟𝑚, ∆𝑦𝑖= (𝑦𝑖 − 𝑦𝑡) /𝑛𝑜𝑟𝑚, where 𝑛𝑜𝑟𝑚 represents the normalization term
Light Head Faster R-CNN with AF-RPN
- Proposal 추출
- region proposal step 이후, 각 detection 모듈별로 top-N1 score의 detection 결과를 proposal set {P}로 선택한다.
- top-N2 score의 proposal set을 추출하기 위해, NMS(IoU=0.7) 알고리즘을 사용한다.
- 이 논문에서는 training, testing 단계에서 N1, N2를 2000, 300을 사용하였다.
- 다음으로 피라미드 레벨 P2, P3, P4에 각각 small, medium, large text proposal group으로 분류한다.
- 파라미터를 공유하지 않는 Fast R-CNN의 detector가 레벨 P2, P3, P4의 각각 할당되었다.
- Fast R-CNN detector는 Light Head R-CNN(large separable conv, PS ROI pooling)을 사용하였다.
- 각 피라미드 별로 2개의 large separable convolution을 사용하였다.

- PS ROI pooling을 사용하였다.
- 각 피라미드 별로 2개의 large separable convolution을 사용하였다.

Training
Loss Functions
- Multi-task loss for AF-RPN
- 각 detection 모듈별로 text/non-text 분류하는 layer, bounding box regression layer 총 2개의 output layer가 있다.
-

- 𝐿𝑐𝑙𝑠(𝑐, 𝑐 ∗) is a softmax loss for classification task
- where 𝑐 and 𝑐 ∗ are predicted and ground-truth labels for each sliding point
- 𝐿𝑙𝑜𝑐(𝑡,𝑡 ∗ is a smooth-L1 loss for regression task
- where 𝑡 and 𝑡 ∗ represent the predicted and ground-truth 8-dimensional normalized coordinate offsets
- 𝜆𝑐𝑙𝑠 and 𝜆𝑙𝑜𝑐 are two loss-balancing parameters
- 𝐿𝑐𝑙𝑠(𝑐, 𝑐 ∗) is a softmax loss for classification task
- Multi-task loss for Fast R-CNN
-
- 𝜆𝑐𝑙𝑠 and 𝜆𝑙𝑜c의 값을 제외하고, AF-RPN loss function과 식이 같다.
- total loss of Fast R-CNN is the sum of losses of three individual Fast R-CNN detectors
-
'Paper Review > Object Detection' 카테고리의 다른 글
| FCOS: Fully Convolutional One-Stage Object Detection (3) | 2025.07.10 |
|---|---|
| Feature Pyramid Networks for Object Detection (1) | 2024.01.11 |